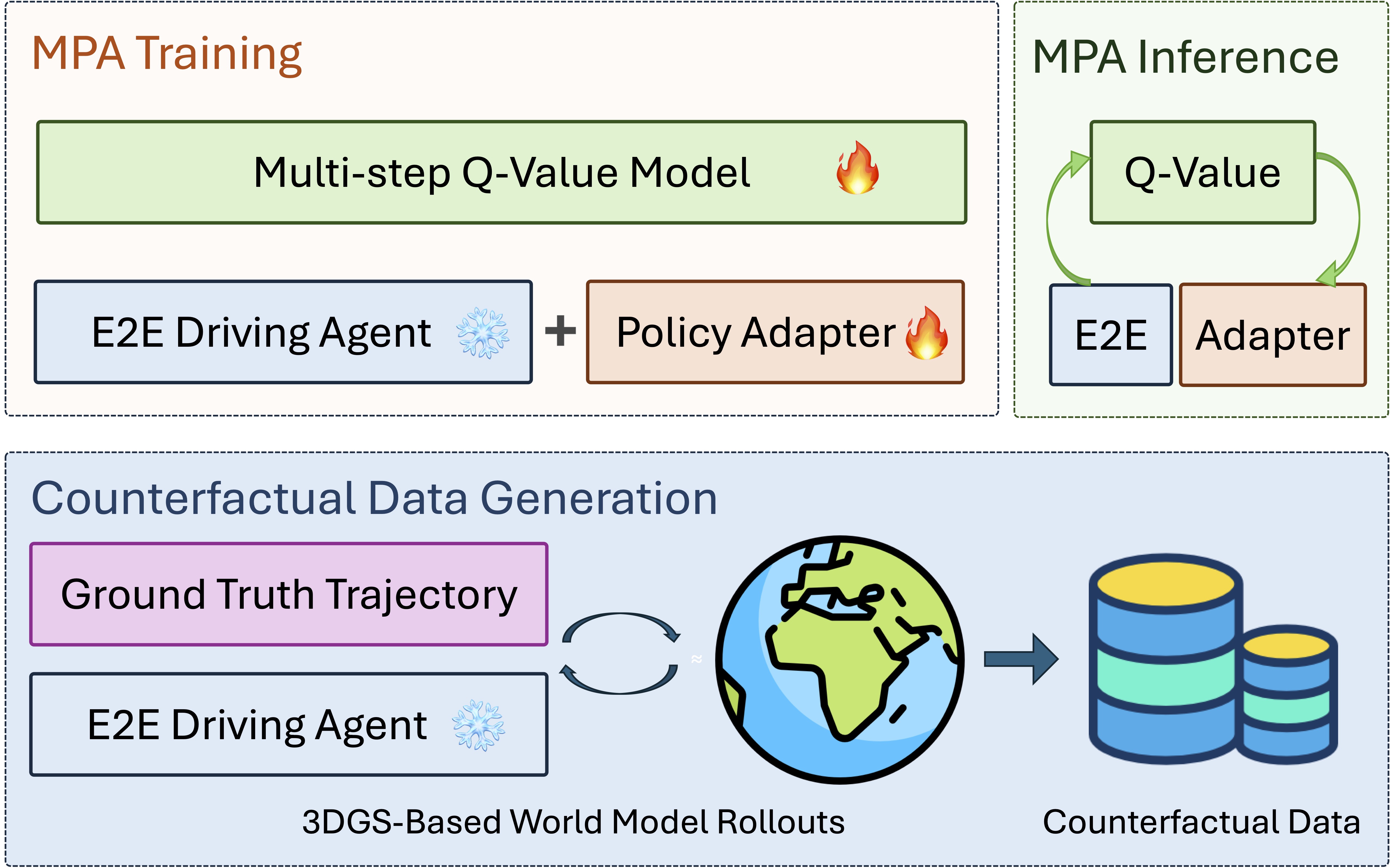
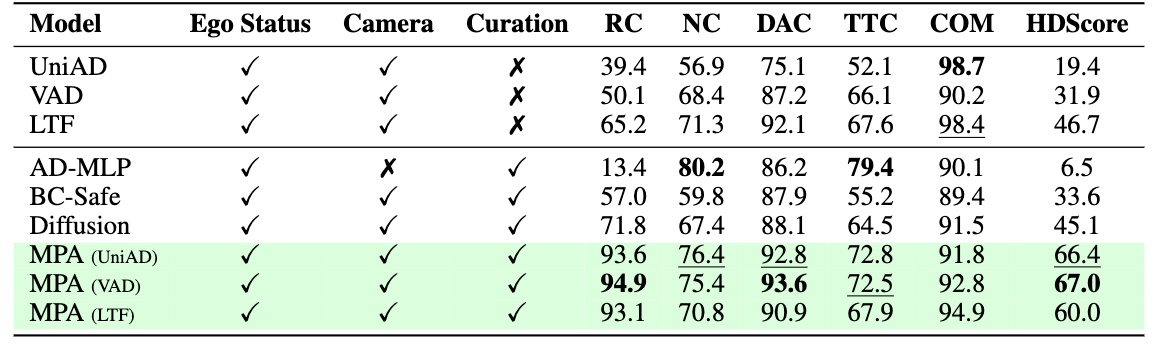
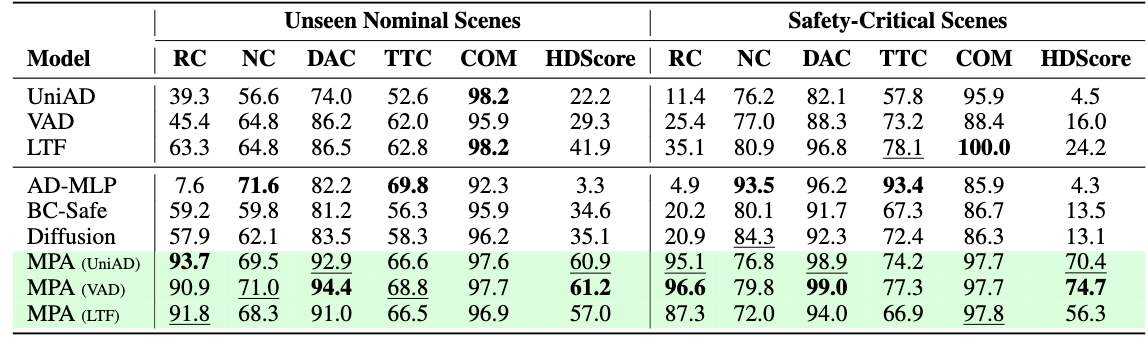
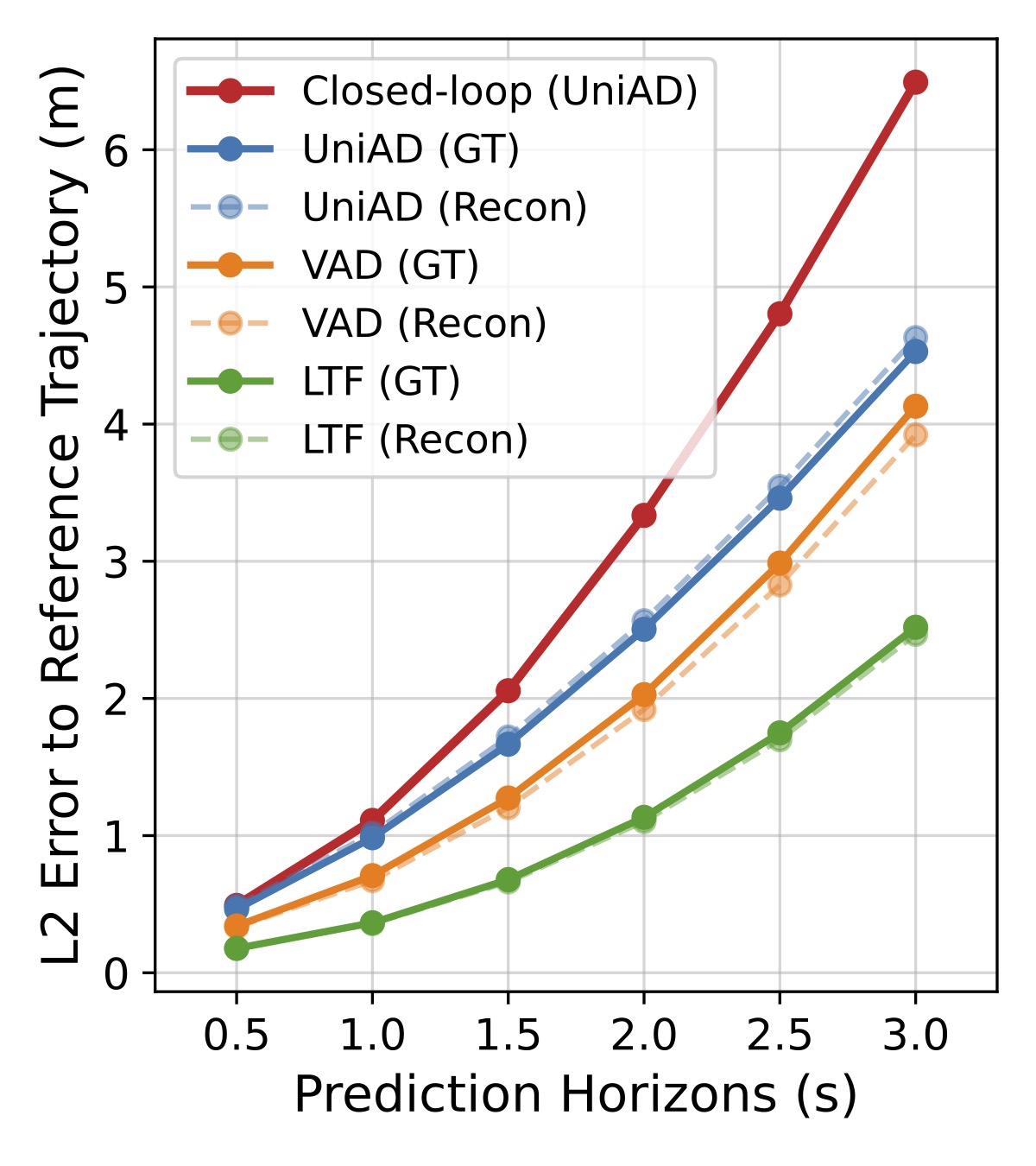
We compare the L2 error of the E2E policy under different data sources on the right figure. We use a 3DGS-based simulator HUGSIM to reconstruct the scenes from the nuScenes dataset and compare the performance difference using ground truth data among all three E2E policies, we see a very close open-loop performance in motion prediction. This confirms the fidelity of the 3DGS-based simulation in its reconstruction quality.
We also find that the open-loop pretrained E2E driving agents like UniAD have performance degradation in closed-loop evaluation due to the distribution shift caused by compounding errors.
We further visualize some qualitative examples for the failure modes below.
Driving off the road to non drive-able area near a construction zone.
Crashing on a stopping vehicle ahead with no collision avoidance.